



StyleGAN2를 이용한 성격 유형별 얼굴 생성 모델 연구 개발 과정 공개! (feat. MBTI)
2021-03-30
 배경
배경
안녕하세요. SPH 데이터 컨설팅팀입니다.
SPH에서는 매출을 가져다 주는 본업과 흥미로운 R&D 주제를 함께 합니다. 각각 비중은 70%, 30%를 차지하죠.
이 연구는 저희 데이터 컨설팅팀에게 흥미로운 R&D 주제, 즉 30%에 해당하는 부분입니다. 한 달이란 짧은 시간 동안 진행된 프로젝트였습니다.
이번에 연구했던 내용들을 이번 포스팅을 통해 공유하려 합니다.
AI 기술 연구/개발을 위한 흥미로운 아이디어가 없을까 고민하였습니다. 당시는 MBTI가 한창 유행했을 때였죠. 지인과 얘기를 나누다가 ‘성격 유형별 관상은 어떤 특징을 지녔을까?’가 궁금해졌습니다.

그렇게 해서 나온 아이디어가 2가지 였습니다.
MBTI 테스트로 나에게 어울리는 이상형을 찾은 후 2세를 찾아보자.
내 MBTI 유형은 어떤 인상을 가지고 있을까?
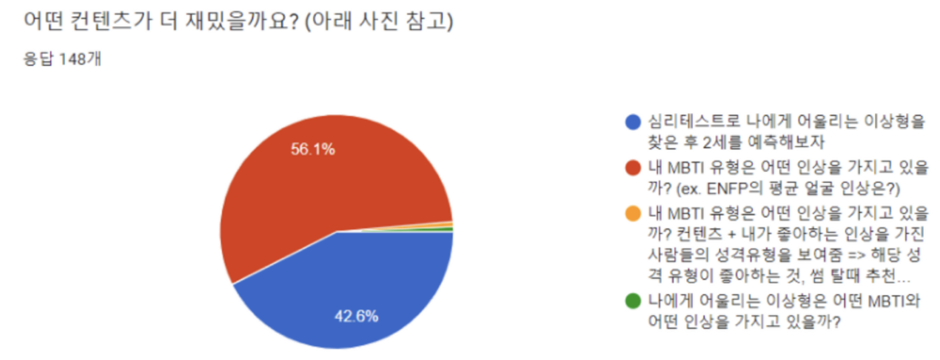
내/외부 투표 결과 2안 (MBTI 평균 얼굴 인상은?이 선택되었습니다.)이 더 많은 표를 얻었습니다.
추가 회의를 거쳤습니다. 그 결과 1안에서 나온 2세를 제외, 이상형이라는 컨셉은 추가하기로 했습니다.

위와 같은 컨셉으로 프로젝트를 진행하기로 했습니다.
지정한 컨셉에 따라 남자, 여자 연예인 각 1000여 장을 수집, 생성 모델을 학습하였고 성격 유형별 얼굴을 뽑아낼 수 있었습니다.
데이터 준비

데이터 수집단계가 쉽지 않았습니다. 모아야 할 데이터는 연예인 중에서도 MBTI 성격 검사를 한 사람의 얼굴 사진이었습니다. 이때 특정 성격의 이미지가 많이 부족했습니다. 특히 ENTJ나 INTJ 유형이 그랬죠. 이 유형들은 일본이나 중국 연예인들을 수집하기도 했습니다.
기술 연구 과정
stylegan → stylegan2 → + ada → + freezeD → + freezeG → pixel2style2pixel
GAN이란?
GAN은 Generative Adversarial Network의 약자로 적대적 생성 신경망이라고 불립니다. 요즘 핫한 딥러닝 기술의 연구 분야 중 하나죠. 판별자(Discriminator)와 생성자(Generator)가 경쟁하듯이 학습하는 게 기본 원리입니다. 이 경쟁 속에서 생성자는 보다 높은 품질의 모조품을 생산할 수 있죠. GAN을 통해 기존 학습한 데이터 분포를 바탕으로 새로운 데이터를 창작할 수 있습니다.
GAN은 computer vision 쪽에서 많이 연구되는 데요. CNN (Convolutional Neural Network)과 결합되었을 때 생성할 수 있는 이미지의 퀄리티가 놀랍습니다. GAN의 종류는 매우 다양합니다. 그 중에서 MBTI 평균 얼굴을 뽑아내기 위해 착안한 GAN은 StyleGAN입니다.
StylegGAN
A Style-Based Generator Architecture for Generative Adversarial Networks 라는 Nvidia에서 나온 논문입니다. stylegan은 기존 GAN을 변형한 형태로, 이미지 생성 시 스타일을 조절할 수 있는 장점을 가지고 있습니다.
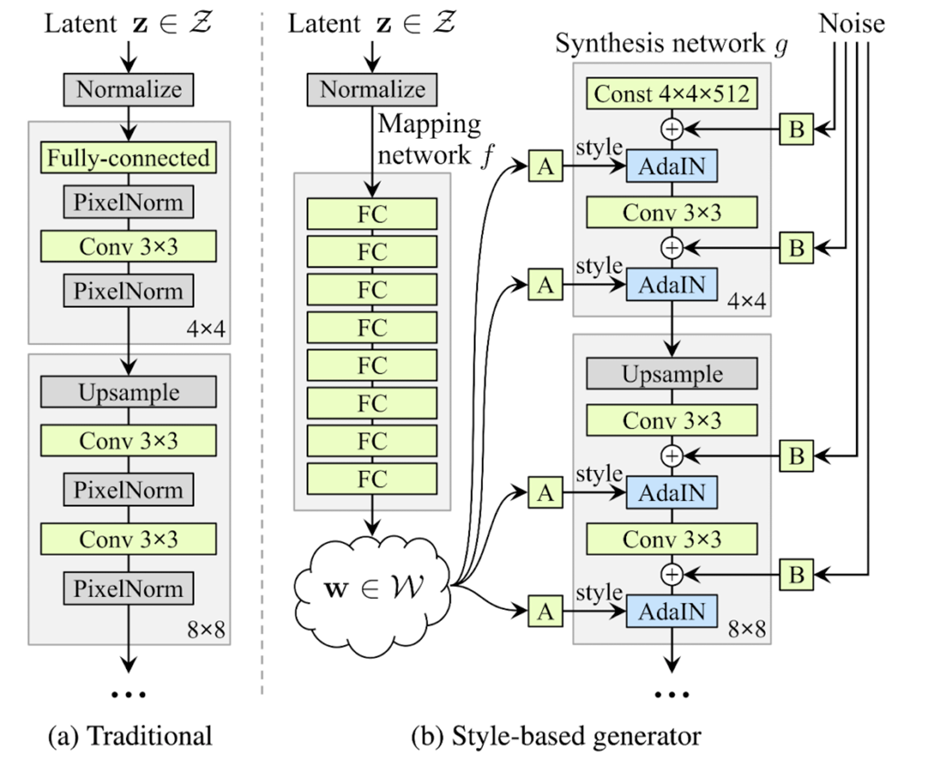
위 그림에서 볼 수 있듯이, 기존 GAN의 경우 임의의 벡터(latent z) 값에서 CNN을 거쳐 이미지를 생성합니다. StyleGAN의 경우 Mapping Network라는 걸 따로 두고 임의의 벡터값을 다른 값으로 변형시킵니다. 이를 w라고 하는데 이게 이미지를 합성하는 네트워크에 입력됩니다. 그냥 입력되는 게 아닌, Affine transformation이라는 선형 변환을 거쳐 스타일이라는 옷을 입고 입력 되죠. 이 스타일은 이미지 생성과정에 해상도마다 들어갑니다.
해상도 마다 들어간다는 게 중요합니다. 왜냐하면 해상도에 따라 이미지가 나타내는 스타일의 종류가 다르거든요. 보통 고차원의 의미를 담고 있는 부분은 4×4와 같이 낮은 해상도입니다. 해당 이미지의 전체적인 형상과 같은 고차원적 의미를 담죠. 1024×1024같이 해상도가 커질 수록 보다 디테일한 의미를 담게 되죠. 가령 머리카락의 모양이라든가 피부의 색상 등이 담기죠. Stylegan은 Mapping Network를 통해 나온 style(A 값)을 조절하여 이미지를 자연스럽게 변화시킬 수 있습니다.
StyleGan을 사용한 이유는 특정 레벨의 style이 성격 유형을 담을 수 있지 않을까 하는 기대에서 였습니다.

하지만 논문에서도 설명한 바와 같이, 물방울 모양의 부자연스러운 무언가가 생성되었습니다. 이를 해결하기 위해 stylegan2를 적용하려 했습니다.
StyleGAN2
Analyzing and Improving the Image Quality of StyleGAN라는 논문에 소개된 기술입니다. stylegan2는 stylegan에서 이미지 생성시 부자연스러운 부분을 제거하고 보다 품질이 좋은 이미지를 생성 시킬 수 있는 버전입니다.
기존 StyleGan에서 사용된 AdaIn(adaptive instance normalization)이 문제가 됐다고 합니다. CNN을 거치며 중간 중간에 생성되는 이미지를 피쳐맵(feature map)이라 합니다. AdaIN을 이용하면 피쳐맵마다 각 평균과 분산으로 normalization 합니다. 즉 입력값의 통계량을 이용하는 것이지요. 그런데 이 방식은 피쳐맵들 사이에 상대적인 크기 차이가 있을 경우, 이 정보를 왜곡합니다.
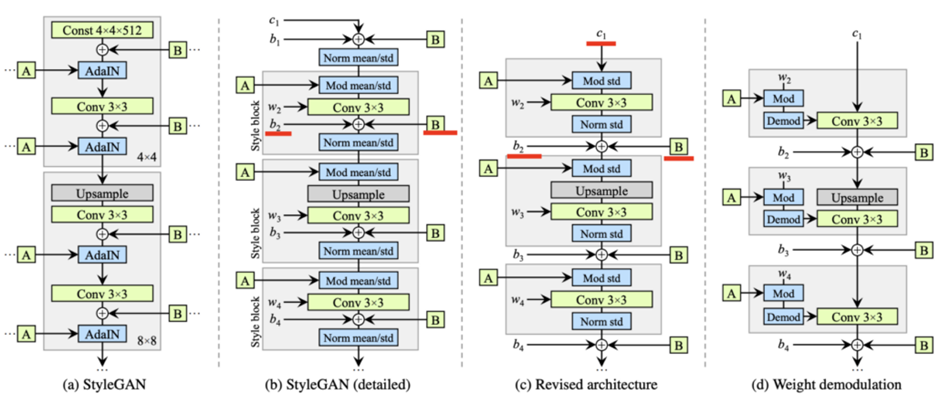
StyleGAN2에서는 문제가 있었던 AdaIN를 수정했습니다. 뿐만 아니라, 아키텍쳐와 학습 방식에도 변화를 주어 생성 이미지의 품질이 더욱 향상 되었습니다.
StyleGAN2 ada
→ Training Generative Adversarial Networks with Limited Data 는adaptive discriminator augmentation(ADA)라는 데이터 증강 기법을 소개한 논문입니다. ADA는 이미지 증강 기법의 일종으로, 판별자에 들어가는 이미지를 다양한 형태로 증강해주어 데이터 부족 현상을 어느 정도 극복하게 해줍니다. 우리가 가진 데이터 세트는 1000장으로 턱없이 부족했습니다. 그랬기에 이 증강 기법은 사막의 오아시스 역할을 해주었죠.
구체적으로 이 증강 기법의 효과가 어떤지 살펴보겠습니다. 기존 StyleGan2의 문제점은 많은 데이터를 필요로 한다는 것이었습니다.
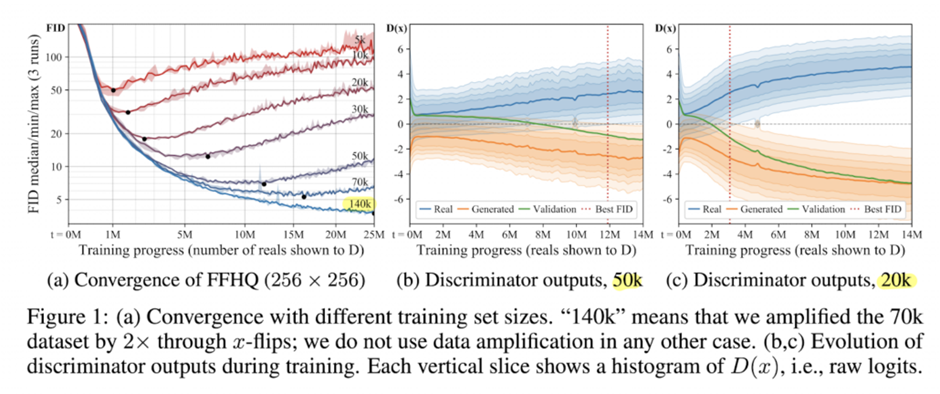
위 그래프(a)에서 FID가 낮을 수록 학습이 잘 된 것입니다. 데이터가 7만장이어도 과적합이 일어납니다. (b)는 5 만 장 데이터셋의 판별자의 출력 값 분포를 나타냅니다. 판별자의 출력이 높을수록 진짜라고 생각하고 낮을수록 가짜라고 생각합니다. 분포를 보면 학습할수록 실제 이미지와 생성 이미지사이의 분포가 벌어집니다. 판별자가 학습이 진행될수록 생성자의 이미지를 가짜로 확신을 하고 있습니다. 이를 보아 생성자가 제대로 된 이미지를 생성하지 못하고 있네요.

그래서 이 논문에서는 위 그림과 같이 다양한 증강기법을 이용해 이미지를 증강합니다. 그런 이미지가 판별자에 들어가 전체적인 학습에 영향을 미칩니다. 이런 원리로 학습 데이터가 비교적 소량이어도 학습이 가능해진 것입니다.
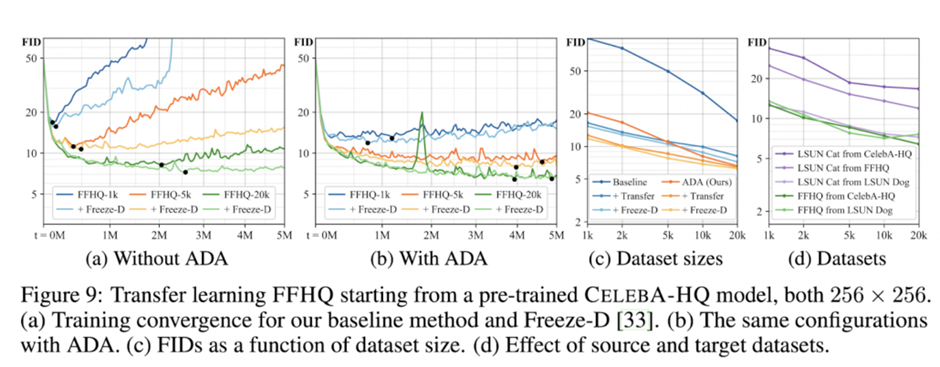
확실히 ADA를 이용할 경우 학습이 좀 더 안정적으로 진행되는 것을 보실 수 있습니다. (a)가 ADA가 없을 때, (b)가 ADA가 있을 때 입니다.
freezeD
Freeze the Discriminator: a Simple Baseline for Fine-Tuning GANs라는 논문에 소개된 내용입니다. freezeD(freeze Discriminator)는 전이 학습(transfer learning) 기술을 이용한 것으로, 기존에 많은 데이터로 학습된 판별자를 최대한 활용합니다.
freezeD의 의미는 freezing Discrimantor, 말그대로 판별자를 얼린다는 의미입니다. 판별자의 일부 층을 얼린다는 건 그 부분을 학습하지 않는 다는 말인데요.
크게 판별자의 네트워크를 전반부의 특징 추출기와 후반부의 분류기로 나눌 수 있습니다. 전반적인 사물의 특징을 추출하는 것을 특징 추출기(feature extractor)라고 하죠.
판별자를 얼린다는 건 판별자의 네트워크 중에 앞단의 특징 추출기를 고정시킨다는 말입니다. 이전에 학습된 네트워크를 최대한 활용한다는 것이죠.
이는 특징 추출기에 쓰인 지식이 도메인이 다르더라도 대부분 유사하기에 가능합니다.
가령 사람의 얼굴 이미지에서 특징을 추출하는 것과 자동차 이미지에서 특징을 추출하는 데 쓰이는 지식. 이 둘사이엔 유사한 부분이 많다는 의미지요.
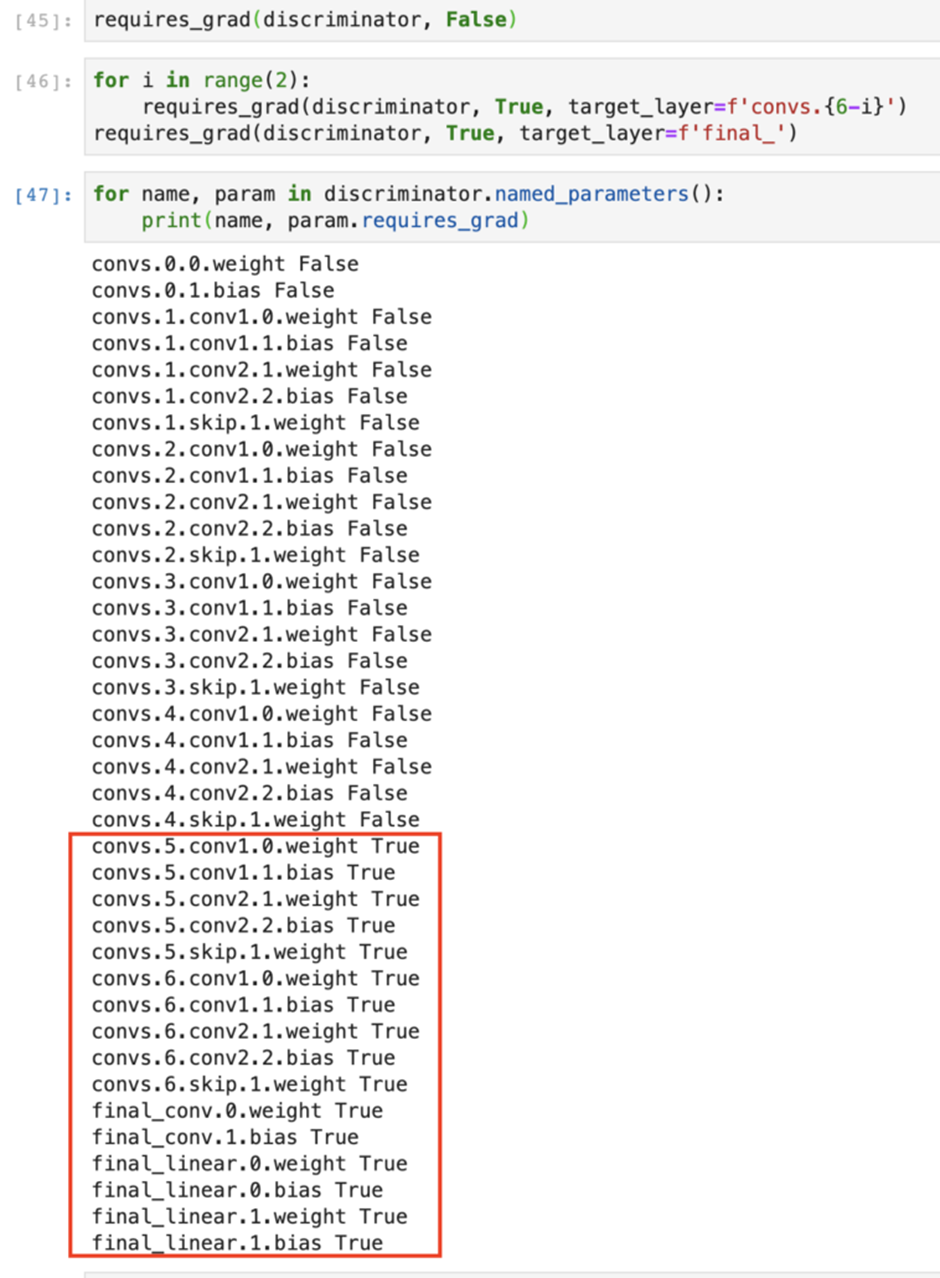
stylegan2에서 위 빨간 박스의 영역 부분만을 학습했습니다.
 22k 학습시
22k 학습시

30k 학습시
뭔가 학습이 진행될수록 이미지가 일그러지는 모습입니다. ada와 freezeD를 통해 이전보단 많이 나아졌긴 했습니다. 그렇지만 학습이 진행될수록 이미지가 깨지는 게 이상하단 생각이 들었어요.
생성자가 학습을 제대로 하지 못한다고 생각했습니다. 15k 기준으로 이미지가 점점 깨지기 시작합니다. 그 전까지는 괜찮았는데 말이죠. 그래서 그 전의 생성자를 최대한 유지하고 싶었습니다.
기존의 생성자에서 미세조정하면 되지 않을까란 생각이 들었죠. 구체적으로는 14k 정도에서의 생성자 네트워크 가중치를 조금만 조정해보면 어떨까? 하는 생각!입니다.
‘생성자를 고정시켜보자!’라는 생각에서 나온게 freezeG 입니다.
freezeG
freezeG(freeze Generator)는 freezeD와 마찬가지로 전이학습 기술을 사용합니다. 논문은 따로 없네요. 생성할 때도, 전체적인 형상에 대한 부분은 기존 지식을 최대한 활용하고, 세부 부분은 학습 데이터에 기반하여 점점 배워나가는 것입니다. freezeD와 freezeG모두 데이터 부족 현상을 극복하게 해주고, 사전 지식을 활용하기 때문에 보다 빠른 학습을 가능하게 해줍니다.
확실히 이전 보단 이미지 생성 퀄리티가 높아졌습니다.
자 이제 각 성격 유형별 평균 얼굴을 구하면 됩니다. 그러기 위해선 성격 유형별로 연예인 이미지를 역변환(inversion)해야 했습니다.
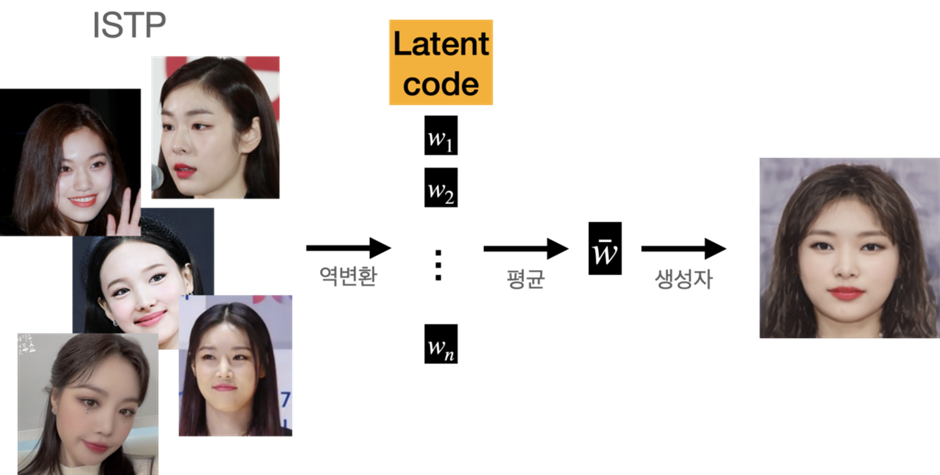
역변환을 통해 이미지를 벡터로 임베딩 시킬 수 있는데요. GAN의 경우 이 임베딩 벡터는 latent code를 의미합니다.
두 이미지 사이의 latent code를 합성후 생성자를 통해 이미지를 생성할 수 있습니다. 결과 이미지들은 아래와 같습니다.







중요한 건 성격별 평균 얼굴입니다. 제 생각은 이랬습니다. latent code의 평균값을 구하고 이를 다시 생성자를 통해 합성한다면, 성격별 평균 얼굴이 구해진다!
그렇게해서 평균 얼굴을 구해봤습니다!

남자 MBTI

여자 MBTI
그런데 예상치 못한 문제가 있었습니다. 이 역변환 과정이 상당히 시간이 오래 걸린다는 겁니다.
저희가 원한건 유저가 사진을 업로드하면, 그 사진과 위 평균 열굴을 합성해서 평균 얼굴이 계속 바껴지는 것이었습니다.
그러기 위해선 실시간으로 역변환이 가능해야 했습니다.
PSP
PSP(pixel2style2pixel)는 이미지를 스타일로 변환한 후 다시 이미지로 변환하는 방법입니다. 기존 GAN의 경우에는 임의의 noise에서 이미지를 생성했습니다.
저희 과제는 성격 유형별로 이미지가 주어지면 이 이미지들을 스타일 차원(latent code)에서 합성하는 것 입니다. 그래서 이미지를 스타일 차원에서 바라볼 필요가 있었죠.
기존 방식의 알고리즘을 사용할 경우 이미지마다 최적화 과정이 매번 일어나 시간이 많이 소요 됐습니다. 이를 해결하기 위해 도입한 기술입니다.
인코더와 맵핑 네트워크를 제외한 다른 부분은 기존 StyleGAN2의 구조와 같기에, 기존에 학습한 지식을 활용할 수 있었습니다.
구체적으로는 styleGAN2 + ada + freezeD + freezeG를 통해 학습했던 network를 pretrained model로 이용하였습니다.
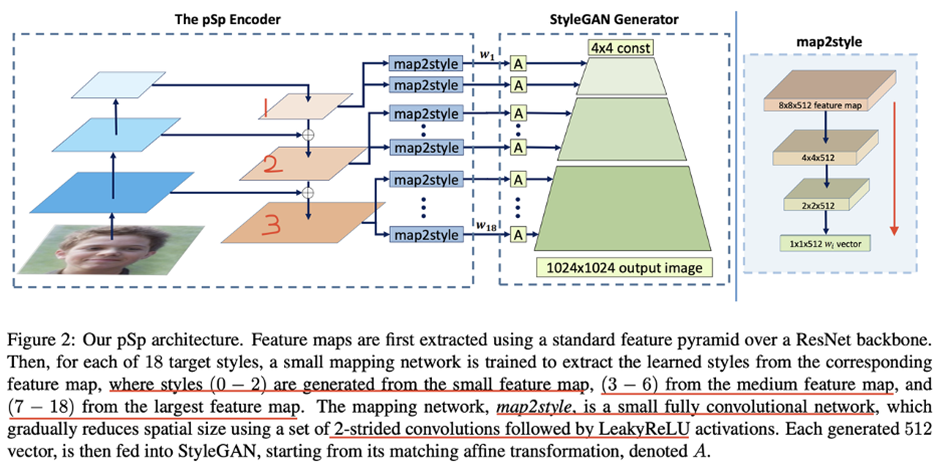
위 그림에서 보듯이 이미지를 입력으로 받습니다. 이 이미지에서 해상도별로 feature map을 style에 맵핑 시킵니다.
기존 styleGAN에서는 입력이 latent vector에, 맵핑 네트워크는 fully connected layer 인 것과 차이가 있습니다.
styleGAN2에서 이미지 역변환 과정은 이미지 마다 일일이 최적화 과정을 거쳐야 했습니다.
하지만 pSp는 인코더(Encoder)를 거치면 style이 바로 얻어지기에 연산 속도가 빠릅니다.
최종적으로는 styleGAN2 생성자를 기반으로한 pSp 네트워크를 채택했습니다. 학습 방법은 ada와 freezeD, freezeG 모두 사용하였지요.
실시간 성격 변화에 따른 얼굴 형태 변화?
pSp를 이용하면 검사하는 와중에 실시간으로 이미지가 변화하는 것도 보실 수 있습니다.
성격 검사 문항은 각 항목마다 E와 I, N과 S, T와 F, P와 J를 구분해줍니다.
만약 위와 같은 과정을 거쳐 평균 E, I, N, S, T, F, J, P를 띄는 얼굴을 안다면 실시간 변화를 줄 수 있습니다.
여기서 알파벳은 MBTI를 구성하는 각 특징을 의미합니다.
E/I : 외향/내향
N/S : 직관/감각
T/F : 사고/감정
J/P : 판단/인식
남녀 각각의 특징은 아래와 같습니다.


특정 이미지를 넣고, 한 항목에서 E가 나왔습니다. 그러면 이 이미지를 좀 더 E(외향적)스럽게 변형시킬 수 있습니다.
E→N→T→P→E→N→T→J→I→S→F→P→I→P
로 성격 검사를 했다고 하면 아래와 같이 이미지가 실시간으로 변하는 겁니다.





위 과정은 베타 버전에선 보실 수 없습니다. 반응을 보고 추후 기회가 된다면 실시간 변화 기능도 구현해보고 싶네요.
후기
이번 MBTI 프로젝트에선 크게 4가지 파트가 있었어요.
설문지 작성 및 전체적인 스토리 라인 기획- 이소린 전임
UI/UX 디자인 – 정보라 대리
서버 구축 및 개발 – 지민철 사원, 이주영 사원
인공지능 관련 연구 개발 – 김도환 전임
모두들 고생 많으셨어요. 간단한 후기 인터뷰를 준비해보았습니다.
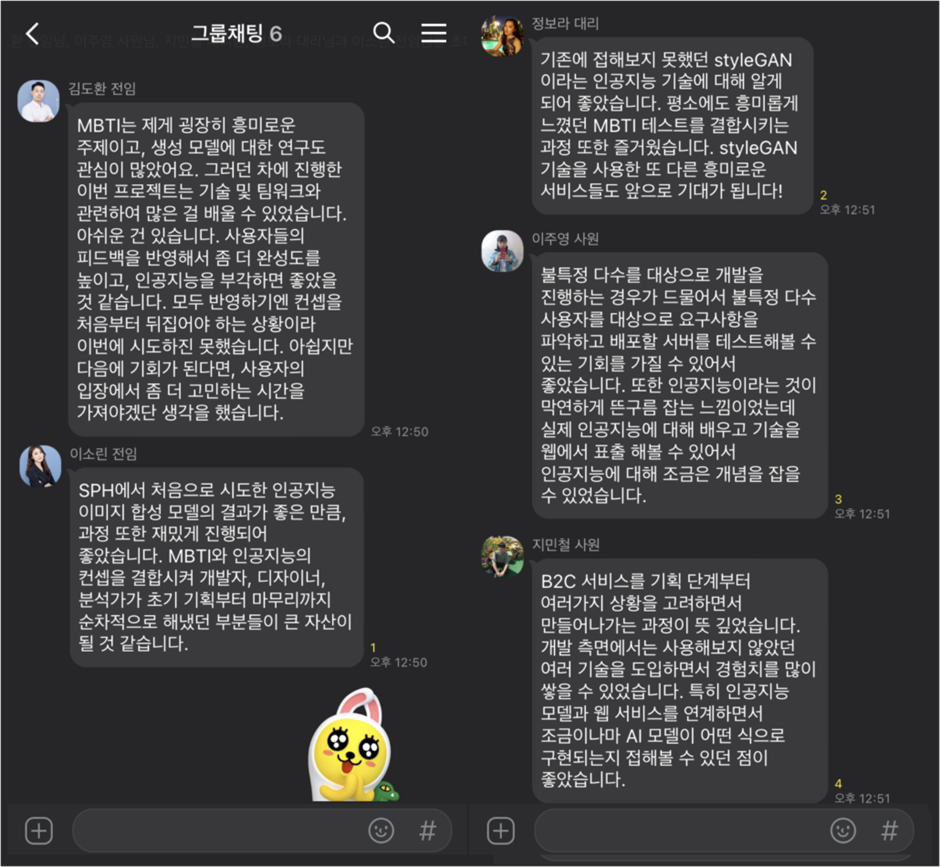
짧은 기간에 개발하여 완성도가 떨어지지만 한 번씩 테스트 해보셔도 재밌으실 거에요.
아래는 검사하러 갈 수 있는 링크입니다! 이상으로 긴 글 읽어주셔서 감사합니다.
다음번에 또다른 새롭고 흥미로운 R&D 파일럿 프로젝트로 찾아 뵙겠습니다.

SPH는 Google Maps, SuperMap, Maxar Technologies 등 다양한 케이스에 존재하는 다양한 제품군을 보유하고 있는 고객의 사례에 꼭 맞는 무료 세미나 및 인적 컨설팅을 제공하고 있습니다. 각 케이스에 더욱 자세한 이야기를 나누고 싶으시다면, 여기에서 문의 주시길 바라며, SPH에서 발행하는 GIS / 로케이션인텔리전스 관련 최신 소식을 받아보고 싶으신 분들은 페이스북 페이지 또는 뉴스레터를 구독해주시길 바랍니다. 감사합니다.
Powered by Froala Editor
SPH는 Google Maps, SuperMap, Maxar Technologies 등 다양한 제품군을 가지고 있으며, 고객의 사례에 꼭 맞는 무료 세미나 및 인적 컨설팅을 제공하고 있습니다. 더욱 자세한 이야기를 나누고 싶으시다면, 여기에서 문의 주시길 바라며, SPH에서 발행하는 GIS / 로케이션인텔리전스 관련 최신 소식을 받아보고 싶으신 분들은 페이스북 페이지 또는 뉴스레터를 구독해주시길 바랍니다

