



2부-1: 머신러닝 비지도학습으로 찾은 최적의 스타벅스 DT, TOP 4 !
2020-08-19
인문사회 데이터기반 스타벅스 DT 입지조건 분석(featuring by AI)

스타벅스 DT 입점 점수를 분석하고 결정하기까지 여러 알고리즘과 모델링과 같은 분석 기법이 사용됩니다. 데이터로 넘쳐나는 세상에서 중요한 변수와 중요하지 않은 변수를 솎아내는 것, 그리고 그 데이터들을 하나로 ‘정의’(Labeling)하는 것이 가장 관건입니다.
저희 SPH 데이터 컨설팅팀은 스타벅스 DT점 입점을 위한 입지 점수를 매기기 위해 머신러닝 지도 학습 및 비지도 학습을 통해 여러 변수들의 특징과 각 DT점이 가지고 있는 특징을 결합하여 의미있는 인사이트를 얻기 위한 과정과 결과를 보여드리려고 합니다.
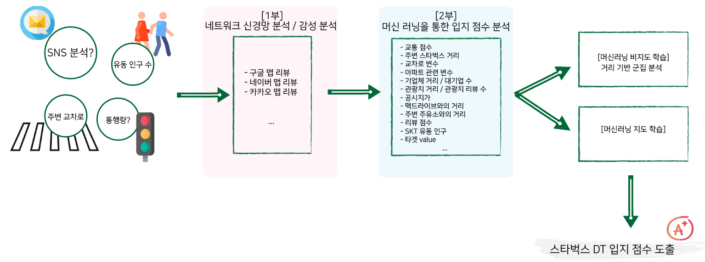

A. [머신러닝 비지도 학습]이란?
머신러닝 비지도 학습은 인간이 눈으로 결정짓지 못하는 것, 혹은 확실한 데이터가 없는 상황에서 다른 변수들이 포함된 빅데이터를 통해 패턴을 학습하여 새로운 데이터에게 학습된 패턴을 기반하여 분석하는 기법입니다. 예를들면 A점의 스타벅스DT가 전망이 좋을 지는 아무도 모릅니다. 하지만 모든 DT점들이 가진 변수들을 취합, 분석하여 비지도 학습을 통해 A점의 스타벅스 DT의 입지 점수를 매길 수 있습니다. 또한 변수의 중요도를 통해서 새롭게 입점을 하고 싶은 곳을 분석하여 학습된 데이터들을 통해 해당 장소의 입지 점수를 예측해 볼 수 있습니다.
군집 분석 K Means 알고리즘은 250여개의 스타벅스DT를 입지 변수 데이터에 근거하여 다섯개의 군집으로 제시했습니다. 스타벅스 DT점 입지 점수를 내는 데 갑자기 군집 분석을 적용한 이유는 무엇일까요? 같은 스타벅스 DT점이라도 고객들의 수요층, 방문 목적, 방문 시간대, 유동 인구 수, 주변 아파트 유무, 관광지 유무등이 큰 변수가 될 수 있기 때문입니다.
예를들어 X점의 스타벅스 DT는 관광 목적으로 입점이 되는 곳이 있으며 Y점은 출퇴근길 고객들을 위한 입점이 목표가 될 수 있기 때문에 모든 DT점들을 같은 선 상에서 모델링을 하는 것은 정확한 점수를 매기는 데 어려운 일이 될 수 있습니다. 그렇기 때문에 군집화를 통해 더 세분화하여 각각의 군집들이 가진 특징을 살펴보는 단계를 가질 것 입니다.
B. 머신러닝이 분류한 스타벅스DT 군집은?

“머신러닝은 스타벅스DT를 5개의 군집으로 자동 분류하였다!”
Kmeans 군집화 알고리즘은 주어진 데이터를 K개의 군집으로 묶는 알고리즘으로, 각 군집과 거리 차이의 분산을 최소화하는 방식으로 작동하는 비지도 학습 기법입니다. 같은 군집의 경우 서로 비슷한 특징을 지니고 있으며, 서로 다른 군집의 데이터들은 이질적인 특징을 지니게 됩니다. 아래 표에서는 250여개의 스타벅스 DT가 5개로 잘 나뉘어져 있습니다. 하지만 군집 결과만 봐서는 왜 1군집이 4개의 DT점이 들어가 있고 4군집이 가장 많은 수의 DT점들이 들어가있는지 설명이 되지 않습니다. 이제, 이 군집을 시작으로 각 군집의 변수에 대한 특징을 살펴볼 것입니다.

C. 5가지 각 군집의 특성은?

1. 교통량 점수
교통량은 굉장히 중요한 변수 중 하나입니다. 교통량이 많다는 것은 잠재 고객이 될 수 있는 유동 인구가 많다는 의미입니다. 빠르게 흘러갈 수 있는 고객들이 ‘내리지 않고 커피를 마실 수 있는’ 플랫폼에 최적화되어 드라이브 스루를 이용하는 최적의 고객이 될 수 있기에, 이 변수를 살펴보겠습니다.
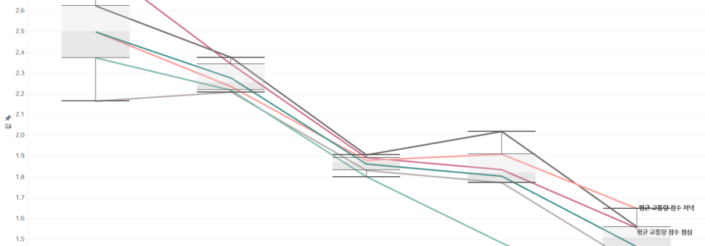
위의 군집별 교통량 점수는 주말, 아침, 점심, 저녁등 여러 분류로 스타벅스 DT를 통과하는 바로 앞 도로가 얼마나 붐비는 지에 대한 수치입니다. Y축의 점수가 높을 수록 교통량이 많은 곳이며 교통량이 적은 곳일 수록 평균 교통량 점수가 낮다고 보실 수 있습니다. 스타벅스 DT 교통량에서 나타난 점수로는 1번 군집이 가장 운전자들이 붐비는 곳으로 나타났으며 5번 군집으로 내려 갈수록 낮은 교통량을 보입니다. 즉, 1번 군집의 스타벅스DT점의 앞 도로는 다른 DT점들에 비해 굉장히 도로 교통량이 많다고 볼 수 있습니다.
2. 관광지 거리 및 리뷰 수
스타벅스 DT는 출퇴근하는 직장인에게만 매력적인 장소가 아닙니다. 관광지 주변의 DT는 일상에 지친 사람들에게 색다른 휴식 공간을 제공하기도 합니다. 특히, 경주 보문로 DT는 스타벅스 1호점으로, 인근 보문로가 경주 관광지로 유명한 곳이죠. 스타벅스가 이 곳을 시작으로 드라이브스루의 포문을 열었던 만큼 관광지는 핵심적인 입지조건중 하나입니다. 이와 관련된 변수인 관광지의 리뷰수와 거리를 분석해 보았습니다.
대한민국에 이름있는 관광지와 스타벅스 DT간의 거리, 그리고 관광지의 리뷰수를 통해 군집들의 차이가 있는 것을 볼 수 있습니다. 예를 들어, 1군집은 관광지 리뷰수는 굉장히 많고, 관광지와의 거리는 가장 가깝기 때문에 굉장히 유명한 관광지 주변의 스타벅스 DT일 수도 있겠다고 추측할 수 있습니다. 반면, 4군집은 관광지 리뷰수는 적고, 관광지와의 거리도 상대적으로 멀기 때문에 스타벅스 DT가 아파트 및 IC 근처의 입점 지역이라 추정할 수 있습니다.
3. 유동 인구 수
앞서 소개한 교통량도 중요한 변수이지만, 교통량은 스타벅스 DT지점에서 운전자를 포함한 전체 유동 인구를 담기에는 한계가 있습니다. 이를 보완할 수 있는 데이터가 유동 인구 수로, 얼마나 많은 사람들이 이동하고 움직이는 지를 나타냅니다. 아래 그래프를 통해 실제 스타벅스 DT지점 기준, 수 백 미터 반경에서 군집별, 요일별 유동인구 수를 나타내 보았습니다.
X축은 군집을 의미하며 Y축은 평균 유동인구 수를 의미합니다. Stack bar 그래프로 표시해봤을 때 1번 군집의 스타벅스DT의 반경 수 백M 이내의 유동 인구수는 어느 요일을 비교해서도 굉장히 많은 유동 인구수를 보입니다. 5번 군집의 금요일 유동 인구수는 2만6천여명으로 5번 군집보다 1번 군집이 10배 이상인 30만명의 유동인구 수를 나타내고 있습니다.
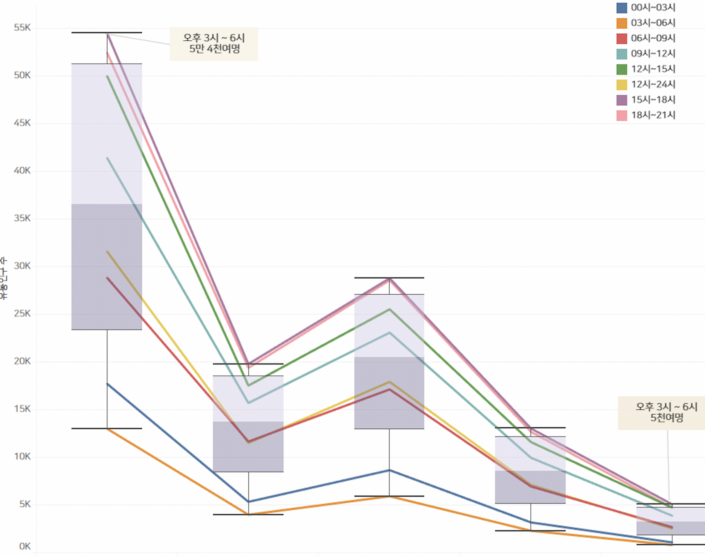
시간에 따른 그래프에서도 1군집은 5군집과 확연히 차이를 보이고 있습니다. 1군집의 스타벅스 DT는, 가장 붐비는 시간대인 15시~18시 사이에 평균 5만4천여명의 유동 인구가 포착되었습니다. 반면, 5군집의 동시간대 유동 인구는 5천여명으로, 1군집의 유동 인구는 5군집의 10배 이상입니다. 즉 1군집이 5군집에비해 10배 이상의 잠재 고객이 있다고 볼 수 있습니다.
4. 리뷰 점수
1부 스타벅스 입지조건 분석(https://www.sphinfo.com/starbucksdt)에서 소개드린 리뷰 점수도 하나의 히든 변수로 볼 수 있습니다. 서비스, 친절, 드라이브스루 이용의 편리함 등이 고객의 입장을 가장 잘 전달한 ‘입소문’의 수치화된 데이터라고 본다면, 이를 통해 어느 군집이 어떠한 ‘평판’을 지니고 있는 지 확인할 수 있습니다.
감성 분석을 통해 산출한 리뷰 점수를 통해 고객의 만족도를 추정할 수 있습니다. 리뷰 점수가 높다면, 고객의 만족도가 높기에 현재의 매출이 괄목할 만한 수치가 아니더라도 미래의 매출은 상승할 여지가 있습니다. 반대로, 어떤 DT점의 경우 현재는 매출이 상당히 높지만 리뷰 점수가 낮아, 매출의 상승세를 유지할 가능성은 낮아 보입니다.
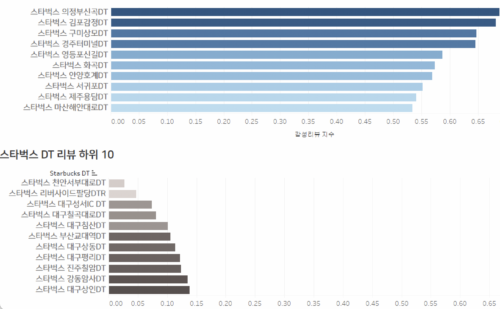
위의 스타벅스 DT점 리뷰를 통해, 비지도 학습에서 나누어진 군집들의 리뷰 점수가 어떻게 분포되어 있는 지 확인해보겠습니다.
아래의 막대 그래프를 보시면 1군집이 평균 0.33807점으로 압도적으로 높은 리뷰 점수를 보유하고 있습니다. 반면 3군집은 상대적으로 낮은 0.31203의 리뷰 점수를 나타내고 있습니다. 즉 1군집의 DT점들은 상대적으로 미래의 매출 지표에도 긍정적인 상승세를 보일 것으로 예상됩니다.

5. 네이버 영수증 리뷰
네이버 영수증 리뷰는 고객들이 실제 스타벅스DT점에 방문하여 구매 후 리뷰를 남기는 형식의 리뷰 플랫폼입니다.
다른 포털 사이트의 리뷰 서비스와 다르게 실제 ‘구매’가 이루어져야 글을 작성할 수 있게 한다는 점에서 매출 짐작에 신뢰성이 높다고 판단하여 모은 데이터입니다. ‘매출’을 짐작할 수 있는 변수로 최근 3개월 간 해당 스타벅스DT를 다녀간 고객들이 남긴 영수증 리뷰와 갯수를 사용하였습니다. 전체 네이버 영수증 리뷰 갯수와 점수 데이터를 사용하지 않은것은 각 지점의 오픈일에 따른 오차가 없도록 하기 위함입니다.
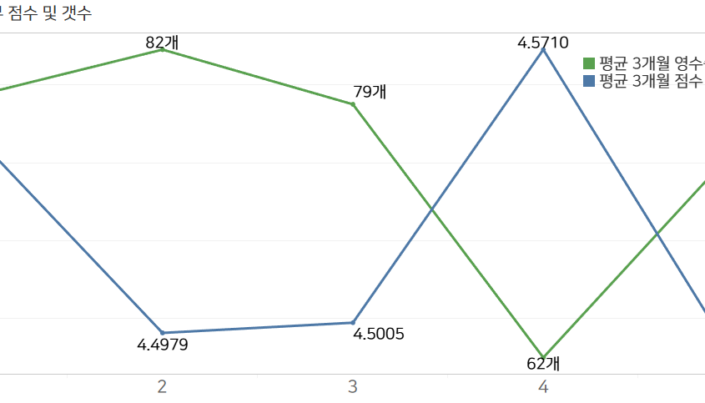
위의 그래프처럼 1군집이 다른 변수들의 결과처럼 1등은 아니지만, 평균 3개월 영수증 개수 부문에서 79개로 상위권을 차지하고 있습니다. 이로보아, 1군집의 현재 매출은 다른 스타벅스 DT에 비해 상대적으로 높을 것으로 판단됩니다.
또한 1군집은 영수증 개수 값이 79개로 같은 3군집과 비교했을때, 리뷰 점수도 높은 점수를 받았습니다. 1군집의 경우, 매출과 고객들의 만족도 둘 다 모두 높다 할 수 있습니다.

1군집은 대부분의 변수들에서 좋은 수치를 지니고 있기 때문에, 굉장히 ‘탐낼만한’ 장소의 DT점임은 분명합니다. Kmeans 군집 분석은 hierarchy 분석이 아니기때문에 특징을 나타낼뿐 어느 군집이 열등하고 우등한지 나타내는 척도는 아닙니다. 하지만 군집별로 변수를 분석하여, 우리가 가지는 기대치에 부합하거나 더 높은 수치를 가지고 있는 DT점들이 모인 곳이 1군집인 것을 확인했습니다. 1군집 중 DT점은 송파나루역, 광주신세계, 온천장역 DT등으로 서울에만 집중되어 있지 않고 고루 분포되어 있음을 알 수 있습니다.

.png)
6. 3년 간 공시지가 상승률 및 평균
공시지가란 건설교통부에서 조사, 평가하여 공시한 토지의 단위 면적당 가격입니다. 물론 부동산을 직접 사고 파는 실거래가와는 다르지만 정부가 세금을 부과할 때 주로 사용하기 때문에 스타벅스 DT가 들어선 장소의 값어치가 얼마나 올랐는 지 가늠해 볼 수 있는 지표가 될 수 있습니다.
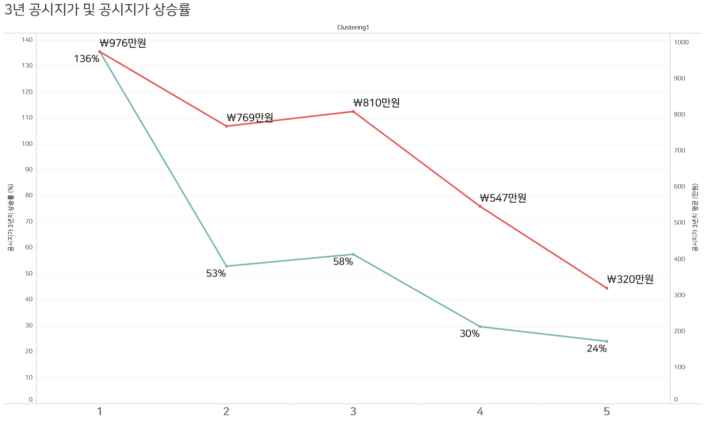
여기서도 1군집이 3년 동안 가장 높은 공시지가 상승률을 보였습니다. 약 136%정도의 상승률을 보이며, 5군집의 24% 상승률의 약 6배이기 때문에 굉장한 차이라고 볼 수 있습니다. 또한 1군집은 평균 단위 면적당 976만원의 공시지가를 보유하며 320만원의 공시지가를 보유한 5군집보다 3배 이상의 가격을 보유한다고 볼 수 있습니다.
위의 군집 분석을 통해, 스타벅스 DT입지조건과 관련된 다양한 변수들에 대한 이해를 넓힐 수 있었습니다. 하지만 비지도학습으로 실제 입지점수를 예측하는데에는 한계가 있습니다. 비지도학습과 달리 지도학습의 경우 target 데이터를 필요로 한다는 단점이 있지만, 적합한 모델이 있을 경우 보다 높은 정확도로 예측이 가능합니다. 다음 포스팅에서 소개드릴 스타벅스DT 입지 점수 예측 분석은 머신러닝 지도학습을 이용한 결과입니다.
1부: 스타벅스 DT 소셜 데이터를 이용한 감성분석 바로가기
3부: 머신러닝 지도학습을 이용한 스타벅스 DT 입지점수예측 바로가기
김도환 데이터 컨설팅 전임 | 이소린 데이터 컨설팅 전임
SPH는 Google Maps, SuperMap, Maxar Technologies 등 다양한 케이스에 존재하는 다양한 제품군을 보유하고 있는 고객의 사례에 꼭 맞는 무료 세미나 및 인적 컨설팅을 제공하고 있습니다. 각 케이스에 더욱 자세한 이야기를 나누고 싶으시다면, 여기에서 문의 주시길 바라며, SPH에서 발행하는 GIS / 로케이션인텔리전스 관련 최신 소식을 받아보고 싶으신 분들은 페이스북 페이지 또는 뉴스레터를 구독해주시길 바랍니다. 감사합니다.
Powered by Froala Editor
SPH는 Google Maps, SuperMap, Vantor, Snowflake, Sigma Computing 등 다양한 제품군을 가지고 있으며, 고객의 사례에 꼭 맞는 무료 세미나 및 인적 컨설팅을 제공하고 있습니다. 더욱 자세한 이야기를 나누고 싶으시다면, 여기에서 문의 주시길 바라며, SPH에서 발행하는 GIS / 로케이션인텔리전스 / AIBI / 데이터비즈니스 관련 최신 소식을 받아보고 싶으신 분들은 페이스북 페이지 (링크드인 페이지) 또는 뉴스레터를 구독해주시길 바랍니다

