



2부-2: 머신러닝 지도학습을 통해서 꼽아본 최적의 스타벅스 DT 장소!?
2020-08-24
인문사회 데이터기반 스타벅스 DT 입지조건 분석(featuring by AI)

지금까지 최적의 입지 변수를 가진 스타벅스 DT 장소들을 찾아보았습니다. 제 2의 최적의 스타벅스 DT점이 되기 위해 ‘어디에’ 스타벅스 DT를 입점시키는 게 좋을 지 찾는 과정의 마지막 단계에 이르렀습니다.
저희 SPH 데이터 컨설팅팀에서는 다양한 데이터로부터 학습과정에 필요한 변수들을 추출하고, 이를 토대로 지도 학습 시행했습니다. 학습 결과 나온 모델로 ‘입지 점수’를 예측할 수 있습니다. 지도 학습 결과 산출된 ‘입지 점수’는 해당 지점이 스타벅스 DT 입점에 얼마나 최적화된 장소인지를 수치화한 결과 입니다.
A. [머신러닝 지도 학습]이란?
머신러닝 지도 학습은 비지도 학습과 달리 명확하게 학습해야 할 정답(혹은 target, 종속변수)이 있습니다. 지도 학습에서는 유동인구, 아파트 세대수, 대기업 정보 등의 feature 데이터(독립변수) 들만 주어지는 게 아닌, 해당 데이터의 정답이 학습시 함께 주어집니다. 이렇게 학습된 모델은 feature를 입력으로 받은뒤, 입지 점수를 출력하는 함수라고 할 수 있습니다.
모델의 성능을 좌우하는 건 양질의 데이터이므로, feature 뿐만 아니라 target 도 매우 중요합니다. 이런 점에서 스타벅스 DT 입지 점수와 가장 관련 깊은 target은 스타벅스 DT의 매출정보가 아닐까 싶습니다.
* 하지만 매출 데이터를 얻을 방법이 없었기에, 저희 나름의 알고리즘을 바탕으로 입지 점수를 선정하고 이를 target으로 하여 모델링을 진행했습니다.
B. 분류화 & 그룹별 머신러닝 기반 분석
SPH 데이터 컨설팅팀은 정확한 머신러닝 알고리즘을 구축하기 위해 스타벅스 DT점들을 총 4분류로 나누었습니다. 전체 스타벅스 DT점들을 하나의 알고리즘으로 분석하는 것보다, 분류 후에 각 그룹별로 예측한 입지 점수가 더 높은 정확도를 나타내는 것을 확인하였습니다. 그 과정과 결과를 설명드리려 합니다.

관광지 그룹으로 분류된 스타벅스 DT점들은 강변, 드라이브 코스, 관광지 근처인 특징들을 가진 DT점들을 분류한 그룹입니다. 또한 실질적으로 ‘유명 관광지’ 근처가 아니더라도 리버사이드팔당DT점과 같이 휴식을 목적으로 찾아오는 지점들을 간추려내었습니다. 이 지점들이 가지는 특징과 입지 변수를 토대로 스타벅스 DT의 입지와 관련하여 예측 분석을 해보았습니다. 예측 분석 후 가장 크게 영향을 미치는 변수들 TOP10을 소개드리려고 합니다.
1) 머신러닝 모델링 과정 및 결과
– 스타벅스 DT점의 Target 변수?
지도학습을 통해 모델이 완성된다면, 이 모델을 통해 스타벅스 DT 입점 전에 내가 선택한 장소가 얼마만큼의 매출을 낼 수 있는 지를 예측할 수 있습니다.
앞서 말씀드린바와 같이, 머신러닝 지도학습에서는 target 변수가 중요합니다. Target 변수가 무엇일까요? 스타벅스 DT 입지 분석에서쓰인 target 변수는 스타벅스 DT를 입점하기에 적합한 장소인지 아닌지를 구분하기 위해서 쓰이는 변수입니다. 좋은 입점 장소를 선택하는 데 있어서 중요한 변수는 각 DT점의 ‘매출’ 및 ‘토지의 가치’등이 있습니다.
여기서 저희가 결정하기 위해 시도했던 변수들은 1.감성 지수가 포함된 Label, 2. 6개월 네이버 영수증 개수, 3. 공시지가 3년치 상승률, 4. 공시지가 3년치 평균입니다. 네 변수 중 다른 독립 변수들과 상관 관계 수치가 가장 높고 많은 독립 변수가 포함된 변수를 target 변수로 선택했습니다.
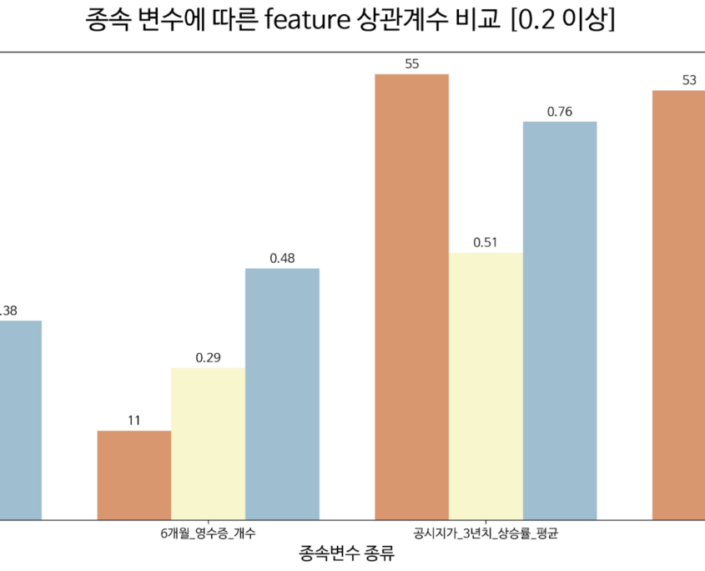
여기서 저희가 관광지에 스타벅스DT를 입점하기에 적합한 장소인지 아닌지를 선택, 구분하기 위한 값으로 선택한 중요 변수는 ‘공시지가 3년치 평균’입니다. 즉 53개의 영향을 미치는 입지 변수들이 평균 66% 정도 ‘공시지가 3년치 평균’과 상관관계가 있다고 할 수 있습니다.
입점 예정인 장소를 머신러닝을 통해 예측하였을 때 공시지가 3년치 평균이 높게 나온다면 그 장소는 여러 독립 변수에 근거하여, 스타벅스DT점으로 높은 매출을 전망할 수 있을 것입니다.
2) 관광지에서 스타벅스 DT 매출 상승을 위한 중요 변수는?
머신러닝 지도 학습 결과, 왼쪽 Y축의 값은 관광지로 분류된 스타벅스DT점들이 가지는 중요 변수들을 나타내었습니다. X축은 입점 장소의 공시지가 상승, 하락에 어떠한 영향을 가지는 지, 변수의 중요도를 뜻합니다. (중요 변수들 중 10개 발췌)
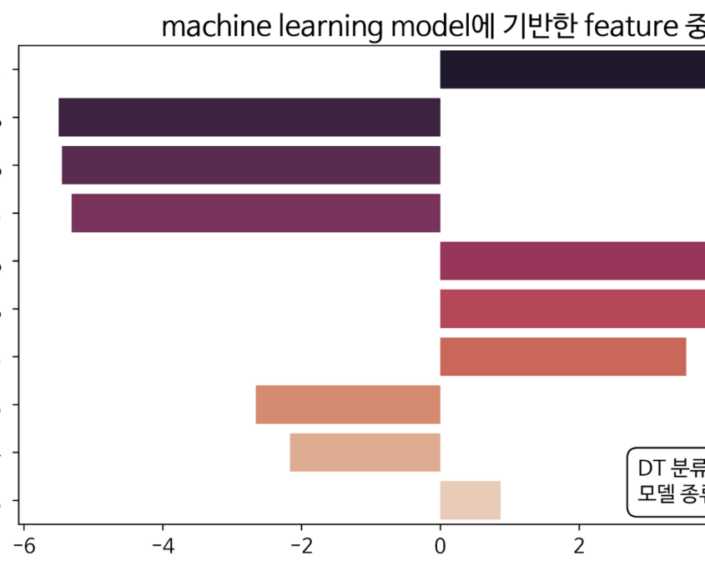
예를 들어, ‘수요일’ 유동인구는 관광지에서 스타벅스 DT를 입점하는 데 영향을 미치는 변수들 중 가장 중요한 변수라고 볼 수 있습니다. 특히, 수요일날 유동 인구 수가 많다면 그 관광지로 분류된 스타벅스DT점은 매출이 높을 가능성이 큽니다.
반대로, 수 km내 주요기업 수는 관광지에 스타벅스DT를 입점하기에는 영향력이 매우 적은 결과값을 가진다고 볼 수있습니다.
이러한 변수의 부정, 긍정적인 관계와 중요도의 높고 낮음을 통해 관광지에 스타벅스DT를 입점하는 데 있어서 입점 장소의 변수값의 중요성을 알 수 있습니다.
**아래는 이러한 머신러닝 알고리즘을 구축하는 과정에 산출한 정확도와 모델 선택 차트입니다. 첫번째 그래프를 통해서 모델링 오차가 mae(평균 절대값 오차) 기준 0.04 정도로 예측을 잘 하는 알고리즘이란 것을 확인할 수 있습니다. 또한 두번째 차트에서 보이는 것처럼, 최적의 성능을 산출하기 위해 10가지 이상의 모델을 학습시키고 이중, 가장 최적화된 StepwiseLinear 모델을 선택했습니다.
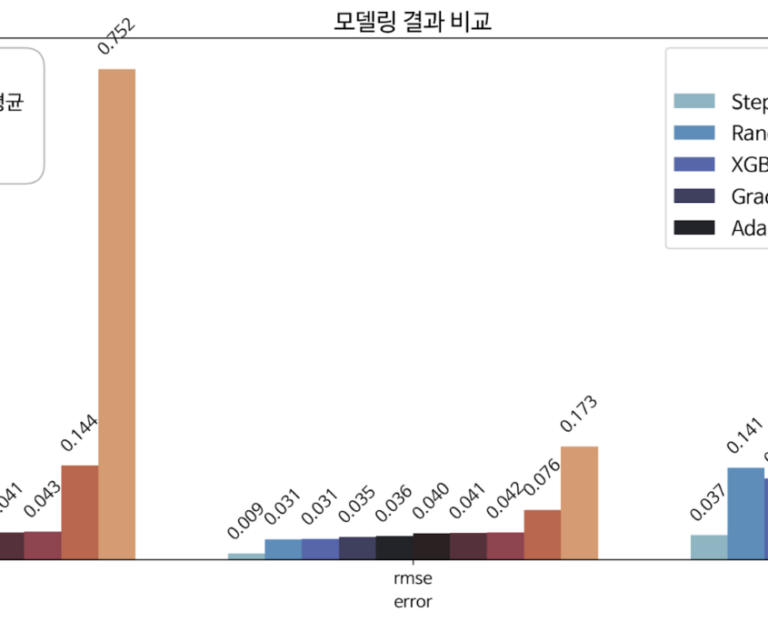
**아래는 머신러닝 모델의 잔차의 분포를 나타냅니다. 잔차의 분포가 정규분포를 따름을 확인할 수 있습니다.
IC 근처로 분리된 스타벅스 DT점들은 대략 80여개로, IC 진입로에 위치하여 있거나 고속도로 근처 및 지리적으로 아파트 쪽을 입구로 향하지 않고 고속도로쪽으로 출입구가 향한 지점들입니다. 또한 정확히 IC근처가 아닐지라도 이 지점들이 가지는 특징들은 주변 아파트 및 거주민들을 위한 고객층이 아닌, 고속도로로 진입하여 다른 지역으로 이동하는 고객층을 위해 위치한 스타벅스 DT점입니다.

1) 머신러닝 모델링 과정 및 결과
위의 관광지로 분류된 스타벅스DT 모델 알고리즘 프로세스와 같이 IC근처로 분류된 스타벅스 DT도 Target 변수 선택이 중요한 단계입니다.
각각의 종속변수에 대해 feature들과의 상관관계를 분석했습니다. 위 차트의 핵심적인 수치를 요약한 그래프는 아래와 같습니다.
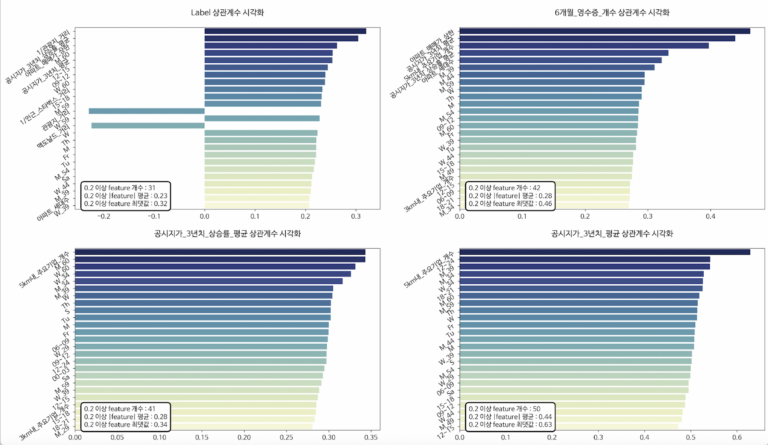
위 그래프에서 볼 수 있듯이, 공시지가 3년 평균 결과의 feature개수와 값이 가장 높습니다. 49개의 다른 입지 변수들이 공시지가 3년 평균값에 평균적으로 44% 영향을 미칩니다. 이를 통해 종속변수를 선택하고 모델링을 진행했습니다.
2) IC 근처에서 스타벅스 DT 입점시 매출 상승을 위한 중요 변수는?
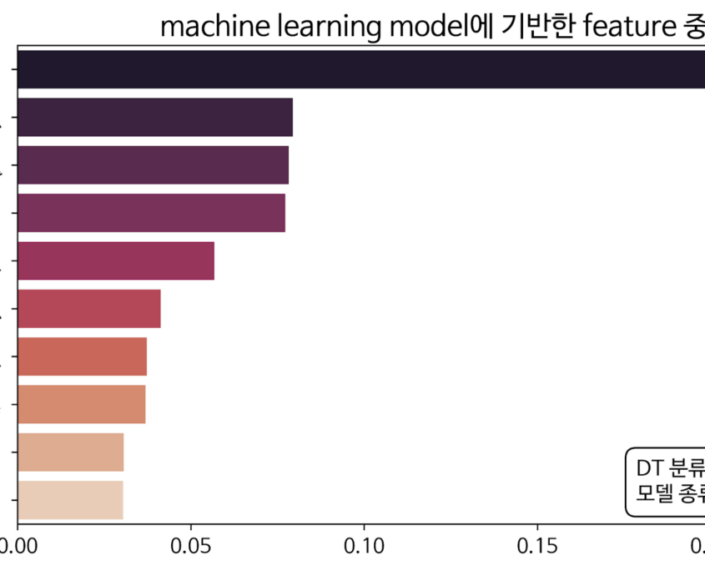
위의 그래프는 IC 근처로 분류된 스타벅스DT점의 매출 상승에 영향을 미치는 요인이라고 볼 수 있는 변수들과 중요도입니다. IC근처에 주요기업 개수가 많을 수록 스타벅스DT 입점에 유리한 변수로 작용할 수 있습니다. 또한, 인근에 스타벅스가 존재한다면 오히려 매출 상승에 좋은 영향을 줄 수 있다는 결과를 가지고 있습니다. 주말에 교통량이 많을 수록 IC근처에 스타벅스 DT 입점이 긍정적인 요인이 될 수 있습니다.
**최적의 성능을 산출하기 위해 가장 최적화된 AdaBoostRegressor 모델을 선택했습니다.
사업체로 분류된 스타벅스 DT점은 주변에 기업 캠퍼스, 산업단지 등이 위치해있어, 회사원들이 주요 고객층으로 자리한 DT점입니다. 대략 40여개의 스타벅스 DT가 사업체 그룹으로 분류되어있으며 이 그룹은 다른 분류 (관광, IC근처, 아파트)와는 다른 입점 변수가 크게 작용할 것으로 예상하고 있습니다.

1) 머신러닝 모델링 과정 및 결과
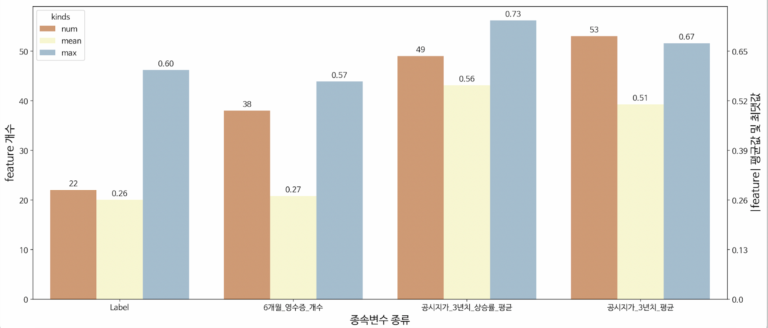
사업체 근처로 분류된 스타벅스DT가 최적의 입점 장소인지 아닌지를 분류해내는 종속 변수를 선택하는 데 있어서 위의 프로세스와 같이 네가지의 변수들을 이용했습니다. 아래 그래프를 통해 53개의 다른 입점 변수들이 공시지가 3년 평균 결과값에 평균적으로 51% 영향을 미친다고 나옵니다.
다른 여타의 변수들보다 높은 변수 상관율과 많은 변수들이 영향을 끼치기 때문에 ‘공시지가 3년치 평균’을 사업체 근처 스타벅스DT 입점의 종속 변수로 사용했습니다.
2) 사업체 근처에서 스타벅스 DT 입점시 매출 상승을 위한 중요 변수는?
.png)
사업체 근처에 스타벅스DT 입점시 중요한 변수는, 머신러닝 지도학습 결과 나타난 위의 변수들입니다. (중요 변수 10개만 발췌)
이를 통해 사업체 근처 스타벅스 DT의 경우, 교통량이 많고 아파트 세대수가 많으며, 인근에 스타벅스가 위치해 있을수록 매출 성장이 높은 곳이라고 분석할 수 있습니다.
앞서 비지도 학습에서 1군집으로 분류된 ‘스타벅스 광주신세계DT’점은 위의 변수들을 어떻게 포함되고 있을 까요?
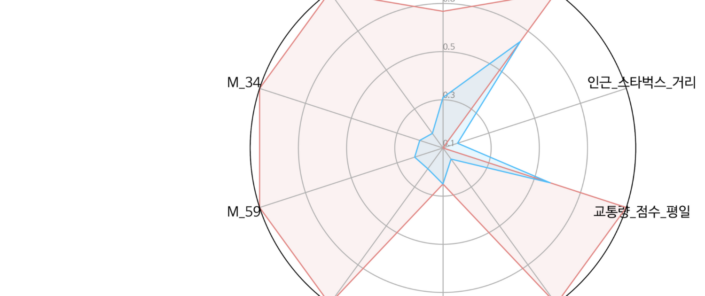
위의 표와 차트는 머신 러닝 지도학습에서 나타난 중요 변수들에 따른 머신 러닝 비지도 학습에서 1군집으로 분류된 광주 신세계DT점 입지 변수 값의 비교입니다. 아파트 매매가 상한 변수를 제외한 모든 변수에서 평균적으로 스타벅스DT점들보다 굉장히 높은 변수 값을 가지고 있습니다. 이를 통해 비지도 학습에서 나온 1군집 사업체는 머신 러닝 지도학습에서 학습한 결과처럼 중요 변수에서 높은 값을 포함한다고 볼 수 있습니다.
**최적의 성능을 산출하기 위해 가장 최적화된 AdaBoostRegressor 모델을 선택했습니다.
아파트 그룹으로 분류된 스타벅스 DT점은 총 90여개로 가장 많은 모집단을 포함하고 있습니다. 이 그룹은 주변에 IC근처 및 고속도로 진입로가 없으며, 유명 관광지가 위치하지않고, 크고 작은 산업체가 존재하지 않는 곳입니다. 반면에 주변에 아파트 및 거주 주택들이 많은 DT 지점입니다.

1) 머신러닝 모델링 과정 및 결과
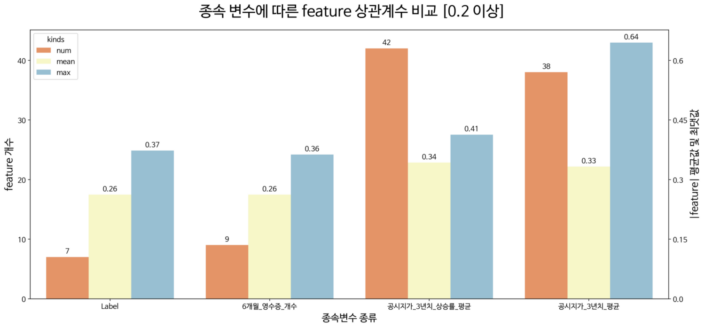
아파트 근처 그룹으로 분류된 스타벅스DT가 최적의 입점 장소인지를 분류해내는 종속 변수를 선택하는 데 있어서 위의 프로세스와 같이 네가지의 변수들을 이용했습니다.
다른 그룹과 같이 아파트 그룹도 공시지가와 관련된 종속 변수가 상관관계가 높았습니다. 반면, 각 종속변수에 따른 모델링 성능의 경우 ‘6개월 네이버 영수증 개수’를 종속 변수로 선택한 모델이 가장 높았기에, 종속 변수로 공시지가를 선택하지 않았습니다. 아마 아파트 일대란 그룹 자체가 이미 공시지가가 평균적으로 높기에, 변수간의 관계를 추정하는데 어려움이 있을것으로 예상됩니다.
아래 그래프를 통해 9개의 다른 입점 변수들이 네이버 영수증 개수 결과값에 평균적으로 26% 영향을 미침을 알 수 있습니다.
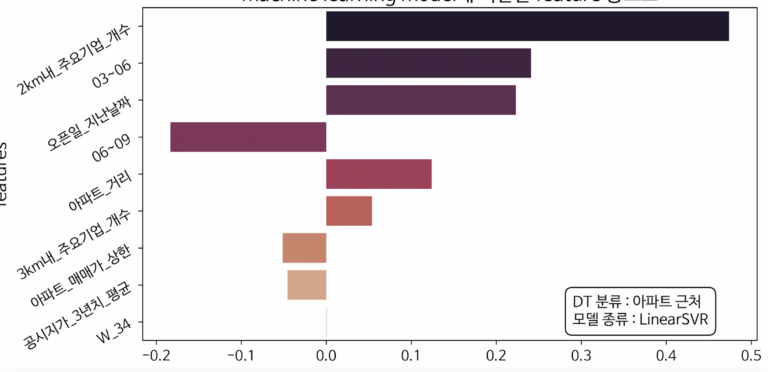
2) 아파트 근처에서 스타벅스 DT 입점시 매출 상승을 위한 중요 변수는?
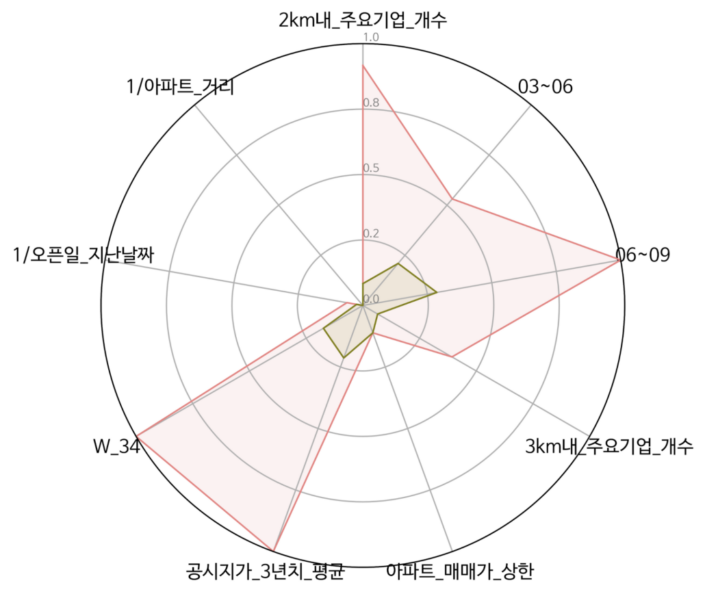

위의 표와 차트는 비지도 학습에서 1군집으로 분류된 송파나루역, 광주상무, 온천장역 DT점과 지도학습에서 스타벅스DT 입점의 중요 변수로 선정된 TOP10과의 변수 값 비교입니다. 세 곳 모두 대부분 아파트로 분류된 DT점들의 평균 값보다 상위 값을 보유한다고 나옵니다. 특히나 유동 인구에서는 평균값보다 크게 상회한다고 볼 수 있으며 아파트 거리도 상대적으로 가깝다고 볼 수 있습니다.
**최적의 성능을 산출하기 위해 가장 최적화된 LinearSVR 모델을 선택했습니다.
앞서 학습한 모델은 해당 지역의 유동인구, 교통량, 아파트 세대수, 주요기업 정보 등을 토대로 공시지가에 기반한 입지점수를 예측하려고 합니다. 이제 이 모델을 이용하여 입지조건을 분석한 결과를 말씀드릴까 합니다.
입점시 높은 매출을 나타낼 것으로 예상되는 장소를 선정하고, 해당 지역의 변수 데이터를 모아 머신러닝 모델에 기반한 입지점수를 산출했습니다. 편의상 위 지역을 미래 전주만성 DT라고 명하겠습니다.
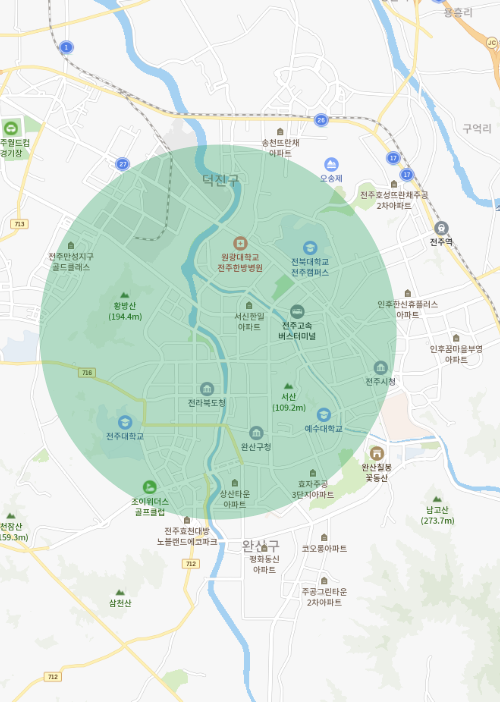
위 지역을 좋은 입지 후보로 선정한 이유는 아래와 같습니다.
국민연금공단 밀접 및 주변에 산업단지들 다수 분포 – 사업체 인근으로 분류 가능
호남고속도로 나들목 근처 위치 – IC 인근으로 분류 가능
위 지점은 사업체 인근 혹은 IC 인근 둘 모두로 분류될 수 있게, 각각의 모델로 예측 분석을 시도했습니다. 각 분류별 분포를 보면 예측값은 평균점수 정도로 높지 않아 보입니다. 하지만 전주시라는 지역 특성을 고려할 경우 위 예측값은 다른 양상을 나타낼 수 있습니다. 이를 확인하기위해, 전주에 위치한 DT점의 평균 입지점수와 미래 전주만성DT점의 입지점수를 비교해볼까 합니다.

전주에는 ‘전주덕진광장DT’, ‘전주백제대로DT’, ‘전주송천DT’, ‘전주평화DT’, ‘전주효자DT’ 총 5 군데의 DT가 있습니다. 5군데 DT의 공시지가 평균값을 산출하고, 모델 예측값과 비교했습니다.
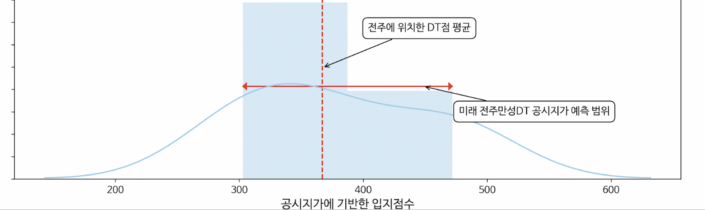
두 가지 모델의 예측 결과를 토대로 산출한, 미래 전주만성 DT의 입지점수 예측 범위와 앞서 소개한 5군데 전주 DT점의 평균값을 시각화했습니다. 입지점수 범위의 최솟값은 사업체용 모델의 예측값이며, 최댓값은 IC용 모델의 예측값입니다. 예측 범위는 전주지역내 스타벅스 DT의 공시지가 평균값 기준, 83% ~ 130% 범위를 나타냅니다. 범위 양 끝 값을 모두 고려할 경우, 전주만성 DT의 입지점수는 전주지역내에 있는 스타벅스DT 평균에 비해 성장가능성이 더 높습니다.
그렇다면 전주만성DT로 선정한 위치의 현재 공시지가 입지점수를 기준으로 미래의 예측값을 비교하면 어떨까요?
현재 점수와 예측 결과 비교
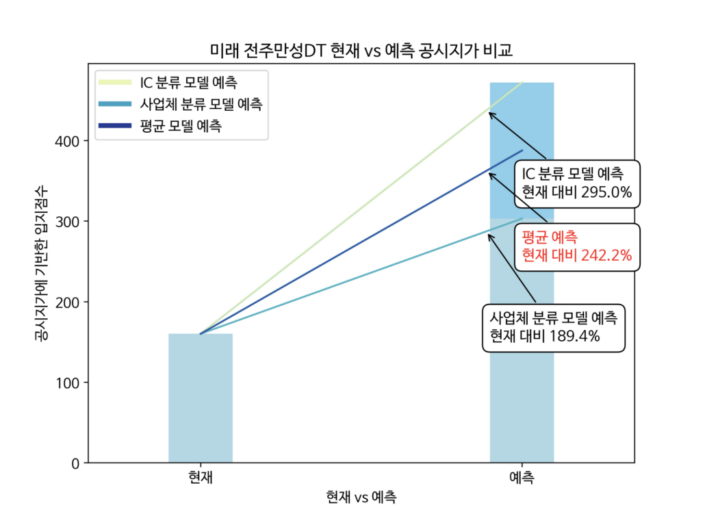
현재 미래 전주만성 DT의 입지점수와 비교하면, IC 분류 모델과 사업체 분류 모델의 예측치는 각각 295%, 189%로 모두 높은 성장을 예측했습니다. 이는 평균적으로 242% 가량의 성장 가능성을 의미하기에, 전주만성에 스타벅스 DT를 입지하는 것은 괜찮은 투자로 보여집니다.
저희 SPH 데이터 컨설팅팀은 스타벅스 DT점의 유동 인구, 교통량, 공시지가 및 스타벅스 DT 입점에 영향을 미칠 수 있는 여러 주변 변수를 머신러닝에 근거한 데이터 분석을 통해 과정 및 결과를 도출해냈습니다.
입지 전략 분석에서 중요한 변수로 꼽힐 수 있는 매출 데이터등의 부재로 예측 결과값이 상이할 수 있습니다. 하지만, 추가적인 내/외부 데이터 소스가 공급될 경우 더 높은 신뢰성을 띈 모델을 구축할 수 있고 한층 더 깊이 있는 컨설팅이 가능할것으로 판단됩니다.
또한, 이번 입지분석 과정을 통해서 저희 SPH에서 구축한 머신러닝에 기반한 데이터 분석 파이프라인은 추후 다양한 산업 분야에서 활용될 수 있을 것으로 예상합니다. 스타벅스DT 입지 분석 뿐만아니라, 다양한 프랜차이즈 (다이소, 올리브영 등)와 호텔 업계(신라스테이, 롯데시티 호텔 등)의 입지조건에 최적화된 입지 선정을 할 수 있는 알고리즘을 구축할 수 있는 가능성을 확인했습니다.
김도환 데이터 컨설팅 전임 | 이소린 데이터 컨설팅 전임
SPH는 Google Maps, SuperMap, Maxar Technologies 등 다양한 케이스에 존재하는 다양한 제품군을 보유하고 있는 고객의 사례에 꼭 맞는 무료 세미나 및 인적 컨설팅을 제공하고 있습니다. 각 케이스에 더욱 자세한 이야기를 나누고 싶으시다면, 여기에서 문의 주시길 바라며, SPH에서 발행하는 GIS / 로케이션인텔리전스 관련 최신 소식을 받아보고 싶으신 분들은 페이스북 페이지 또는 뉴스레터를 구독해주시길 바랍니다. 감사합니다.
Powered by Froala Editor
SPH는 Google Maps, SuperMap, Vantor, Snowflake, Sigma Computing 등 다양한 제품군을 가지고 있으며, 고객의 사례에 꼭 맞는 무료 세미나 및 인적 컨설팅을 제공하고 있습니다. 더욱 자세한 이야기를 나누고 싶으시다면, 여기에서 문의 주시길 바라며, SPH에서 발행하는 GIS / 로케이션인텔리전스 / AIBI / 데이터비즈니스 관련 최신 소식을 받아보고 싶으신 분들은 페이스북 페이지 (링크드인 페이지) 또는 뉴스레터를 구독해주시길 바랍니다

